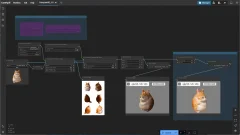
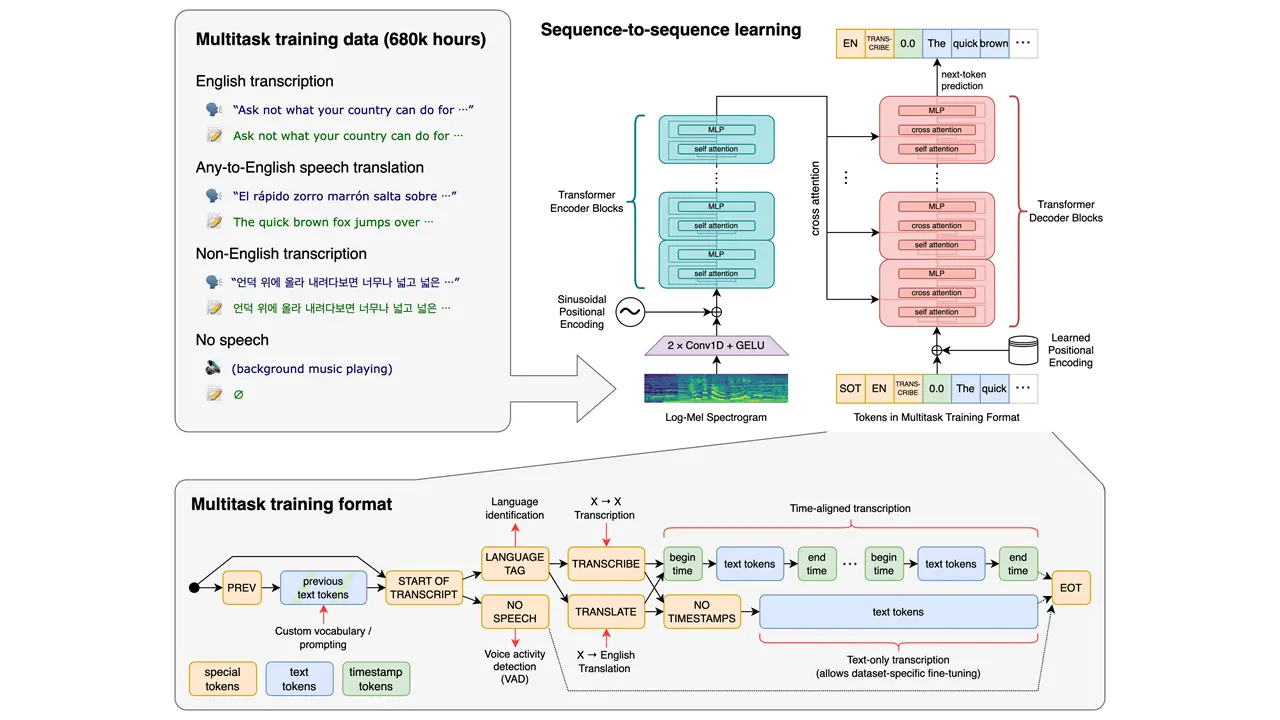
Whisperは汎用の音声認識モデルで、さまざまな音声データセットでトレーニングされています。多言語音声認識、音声翻訳、言語識別など、マルチタスクに対応しています。

実行環境
| OS | Windows11 24H2 |
| whisper | PyPI openai-whisper 20240930 |
ソフトウェア要件
インストール前に必要なソフトがあります。
Git
Gitは分散型バージョン管理システムで、GitHubのリポジトリ管理に使用されます。
Miniconda
condaを使用して、仮想環境を作成します。
FFmpeg
音声・動画の処理を行うツールです。
インストール
Anaconda Prompt (miniconda3)を開きます。
フォルダ作成
md Whisperディレクトリ移動
cd Whisper仮想環境を作成
conda create -n whisper python=3.11仮想環境をアクティブ化
conda activate whisperPytorchをインストール (v2.5.0 CUDA 12.4)
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu124Whisperをインストール
pip install openai-whisper推論
以下の複数のモデルがあります。英語専用の.enモデルは、モデルサイズが小さいほど高いパフォーマンスを発揮しますが、サイズが大きくなるにつれてその差は小さくなります。また、turboモデルはlarge-v3を最適化したバージョンで、精度の低下を最小限に抑えながら、より高速な文字起こしを実現します。
| 多言語モデル | 英語専用モデル | 必要VRAM | 相対速度 |
|---|---|---|---|
| tiny | tiny.en | ~1 GB | ~10x |
| base | base.en | ~1 GB | ~7x |
| small | small.en | ~2 GB | ~4x |
| medium | medium.en | ~5 GB | ~2x |
| large | N/A | ~10 GB | 1x |
| turbo | N/A | ~6 GB | ~8x |
次のコマンドは、largeモデルを使用して音声ファイル(audio.mp3)の文字起こしを行います。mp3のほか、flacやwav形式にも対応しています。
whisper audio.mp3 --model largeその他のオプションについては、以下のコマンドで確認できます。
whisper --help結果はファイルとしてフォルダ内に保存されます。