RVC Text-to-Speech WebUIでは、edge-tts(Microsoft Edgeのオンライン音声合成サービス)で生成した音声をRVCで変換することができます。ここでは、Windowsローカル環境でのインストール方法と使い方を紹介します。

ソフトウェア要件
RVC Text-to-Speech WebUIをインストールする前に必要なソフトがあります。
Git
GitHubからリポジトリをクローンするのに使います。
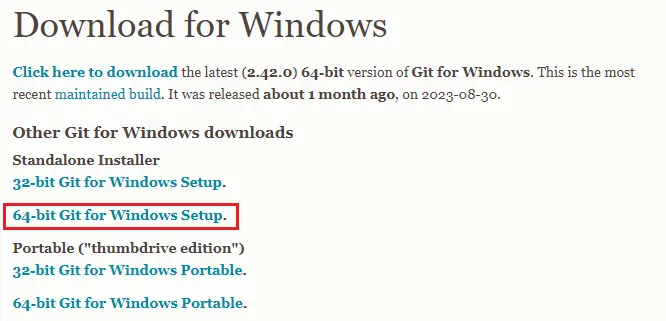
64-bit Git for Windows Setup.をダウンロードしてインストールしてください。
Python 3.10
今回はPython 3.10.9をインストールしました。マイクロバージョンは後方互換性が高いので新しいものでも大丈夫だと思います。
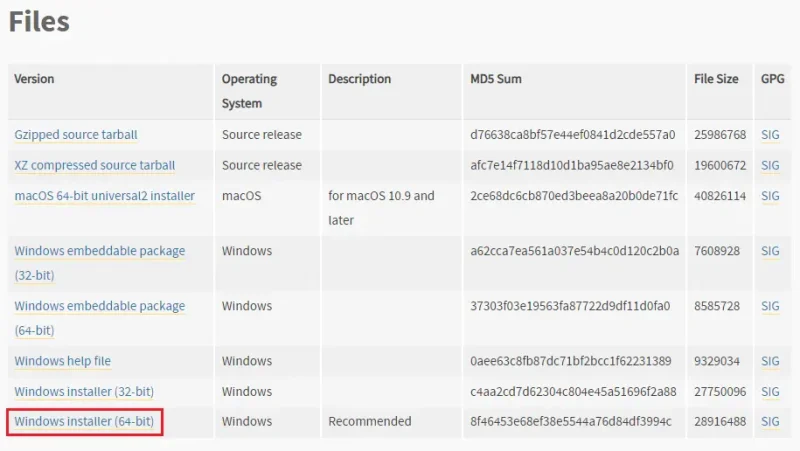
Windows installer (64-bit) ダウンロードして起動
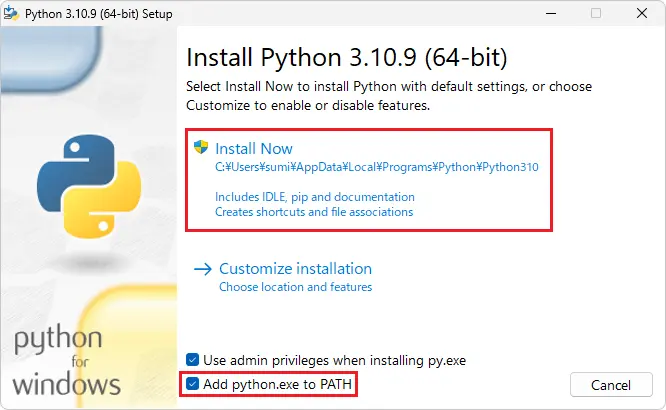
Add python.exe to PATHにチェックを入れてインストールを進めてください。
Microsoft C++ Build Tools
C++ライブラリとアプリケーションをコマンドライン上でビルドするためのツールです。
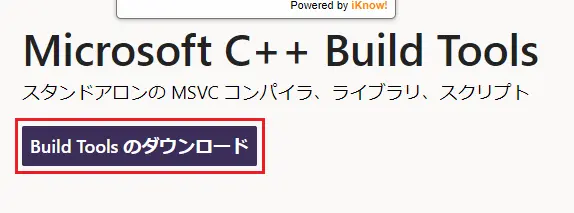
Build Toolsをダウンロードして起動
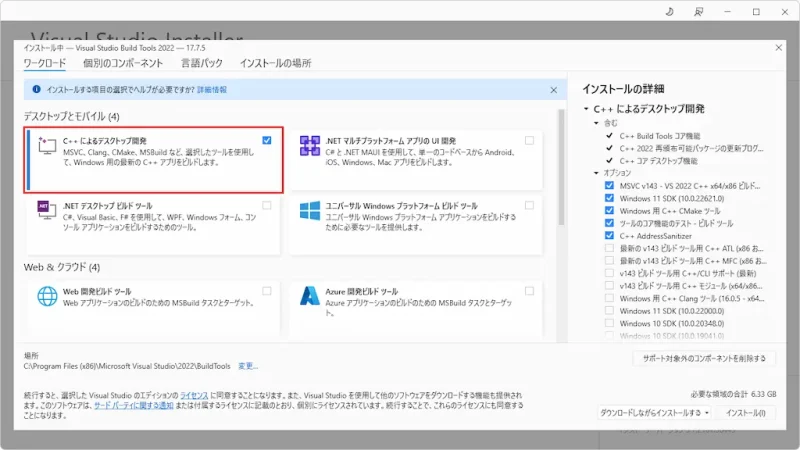
C++によるデスクトップ開発にチェックを入れてインストールしてください。
インストール
ここからはコマンドプロンプトを使ってのインストール作業になります。コマンドプロンプトを開いたら次のコマンドを順番に実行していってください。
インストールするフォルダに移動する(今回はCドライブ直下にしました)
cd C:\GitHubのリポジトリをクローンする
git clone https://github.com/litagin02/rvc-tts-webui.gitフォルダ移動
cd rvc-tts-webuiHugging Faceからモデルをダウンロード
curl -L -O https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.ptcurl -L -O https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt仮想環境を作成(仮想環境の名前はmyenvとした)
python -m venv myenv仮想環境をアクティブ化
myenv\Scripts\activatePyTorchのインストール(NVIDIA GPUを使用する場合)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118必要な依存関係をインストール
pip install -r requirements.txtとりあえずここでインストール完了です。一旦コマンドプロンプトを閉じてください。
RVC用モデルを配置
RVC用モデルが1つはないと起動エラーがでます。weightsフォルダ内に以下のように配置してください。
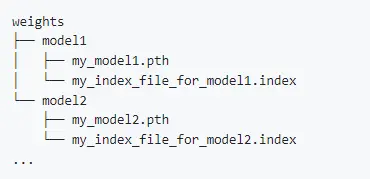
各モデルフォルダ内に1つのpthファイルと、1つのindexファイル(なくても動く)を配置してください。フォルダ名はモデル名として表示されます。
パス名に非ASCII文字(日本語や全角の英数字記号など)は含まないでください。
RVC用モデルは無料配布や販売している方がいます。自分で作成してみたい方は以下の記事のモデルを作成するをご覧ください。
起動方法
コマンドプロンプトを起動します。
インストールディレクトリへ移動(自身のインストール先フォルダのパス)
cd C:\rvc-tts-webui仮想環境をアクティブ化
myenv\Scripts\activate起動
python app.pybatファイルの作成
毎回コマンド入力が面倒な方へのbatファイルの作成方法です。
メモ帳を開き以下のテキストを貼り付けたら、名前をつけて保存で拡張子を.batにして保存してください。
call "myenv\Scripts\activate"
python app.py
pause作成したbatファイルはrvc-tts-webuiフォルダ内に置いてください。作成したbatファイルを起動することでWebUIまで立ちあがります。
RVC Text-to-Speech WebUIの使い方
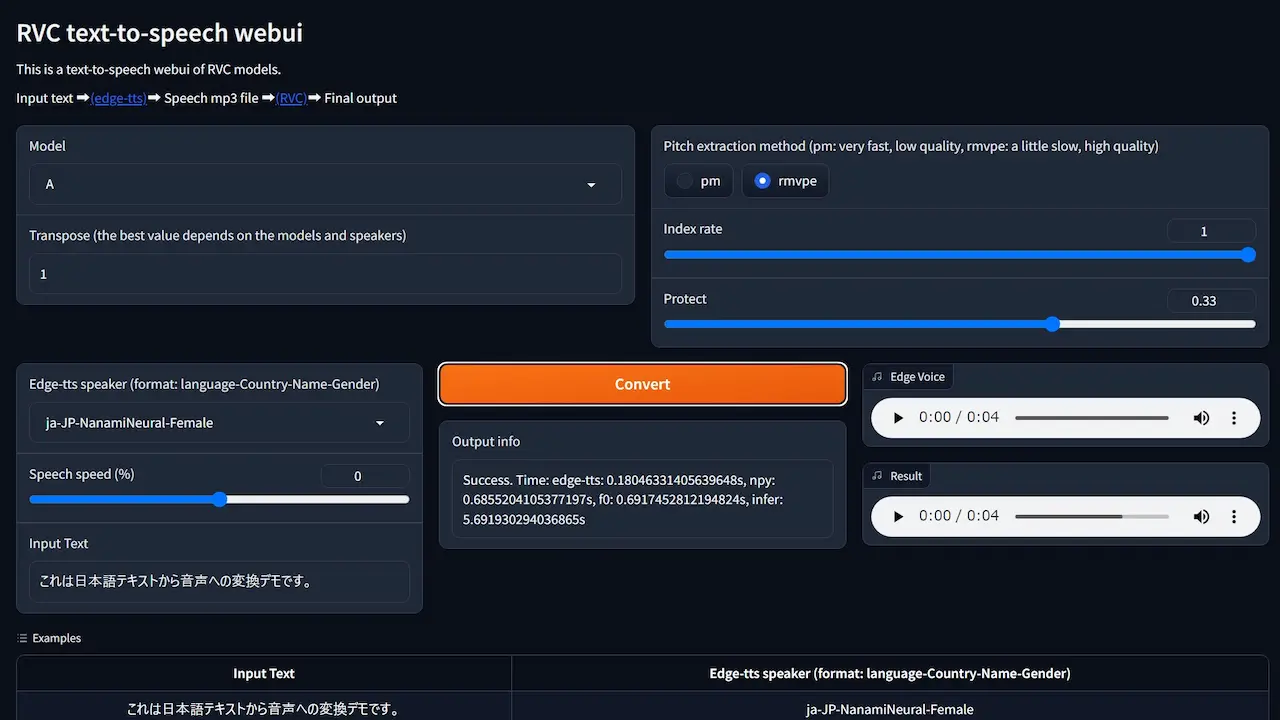
WebUIはシンプルで複雑な設定は特にありません。
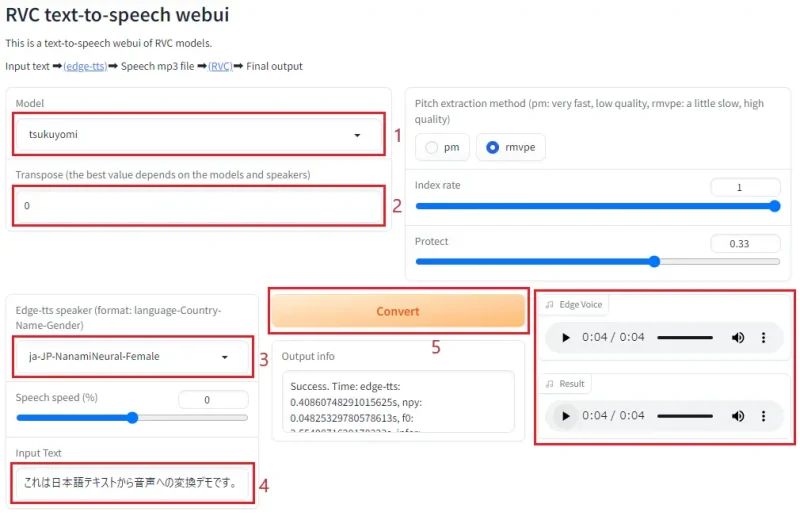
- RVC用モデルを選択
- ピッチ変更
- edge-ttsの言語選択。日本語は男性のKeitaと女性のNanamiがあります。
- 喋らせるテキストを入力
- Convertで生成
- edge-ttsの音声とRVC後の音声が出力される
今回紹介したのはTTSの音声を変換したものですがVALL-E Xというすごい技術があります。興味のある方はご覧ください。