FramePackは、HunyuanVideoモデルをベースに開発された次世代の動画生成フレームワークで、低VRAM環境でも一貫性のある長尺動画を生成できます。ただし、動画生成には相応の処理時間がかかるため、効率的に動作させるための高速化ライブラリの導入方法を紹介します。

実行環境の確認
FramePackは、Windows向けのワンクリックパッケージとして提供されているポータブル環境です。
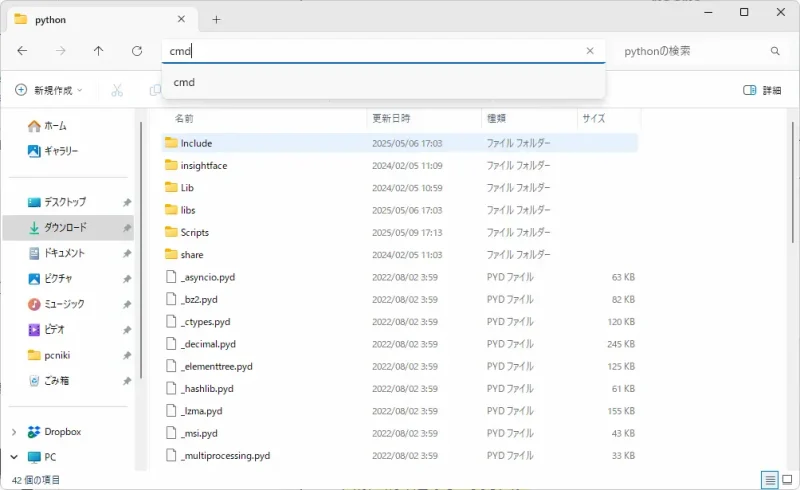
framepack_cu126_torch26\system\pythonフォルダを開きます。アドレスバーに「cmd」と入力してEnterを押すとコマンドプロンプトが起動します。
Pythonのバージョンを確認
python --version
インストールしているパッケージを確認
python -m pip list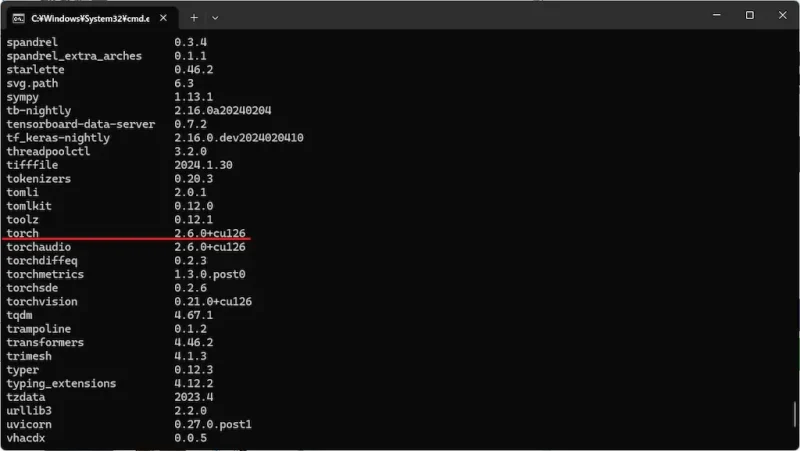
現在の環境は以下のとおりです。
- Python 3.10
- PyTorch 2.6.0
- CUDA 12.6
ライブラリについて
インストール可能な高速化ライブラリには以下の3種類があります。
- xFormers
- FlashAttention
- SageAttention
これらはすべて同時にインストール可能ですが、SageAttentionが優先的に使用されるため、xFormersやFlashAttentionは利用されない可能性があります。併用による効果は不明のため、導入はお好みで判断してください。
| モード | 推論時間(1秒動画) |
|---|---|
| デフォルト | 07:10 |
| xFormers | 05:59 |
| SageAttention | 04:56 |
SageAttentionの導入により、デフォルトに比べ約30%の高速化が確認できました。FlashAttentionは、速度・品質の両面でSageAttentionより劣るようなので、単体での使用はしなくてよいかと思います。
ライブラリのインストール
xFormers
xformersのインストール
python -m pip install xformers==0.0.29.post3 --index-url https://download.pytorch.org/whl/cu126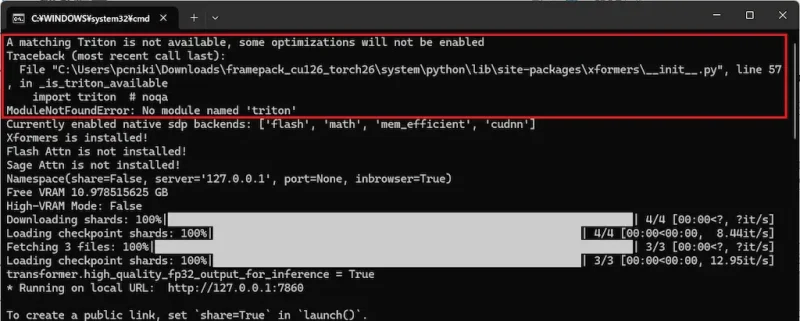
インストール後、FramePackを起動すると「Tritonが見つからず一部の最適化が有効になりません」と表示されますが問題なく動作します。インストールしたい場合は、SageAttentionのTritonのインストールをご覧ください。
FlashAttention
flash_attn ビルド済みホイール(非公式)をインストール
python -m pip install https://huggingface.co/lldacing/flash-attention-windows-wheel/resolve/main/flash_attn-2.7.4%2Bcu126torch2.6.0cxx11abiFALSE-cp310-cp310-win_amd64.whlSageAttention
SageAttentionを使用するには、Tritonの導入が必要です。
python_3.10.11_include_libs.zipをダウンロードして解凍します。中にある「include」と「libs」の2つのフォルダをframepack_cu126_torch26\system\pythonフォルダ内にコピーします。
triton-windowsのインストール
python -m pip install triton-windows==3.2.0.post18sageattention ビルド済みホイール(非公式)をインストール
python -m pip install https://github.com/woct0rdho/SageAttention/releases/download/v2.1.1-windows/sageattention-2.1.1+cu126torch2.6.0-cp310-cp310-win_amd64.whlアンインストール方法
不具合などが発生した場合は、パッケージをアンインストールしてください。
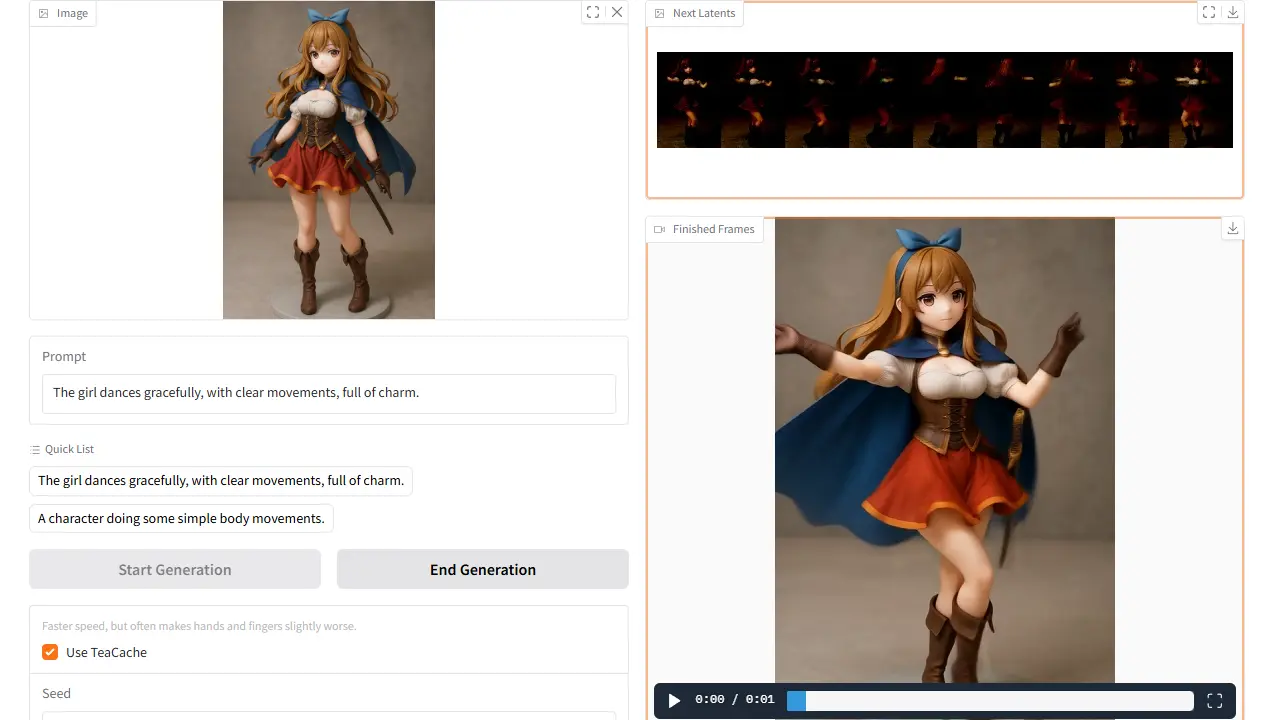
python -m pip uninstall sageattention生成結果
SageAttentionを導入した状態で、5秒間の動画を生成しました。構図や品質をあまり損なうことなく、推論時間を短縮できました。