
FLUX.1のオリジナルモデルは、ファイルサイズが大きくVRAMが少ない環境では扱いにくいです。ここでは、複数の量子化されたモデルの紹介とそれぞれの生成結果を比較しました。

ベースモデル
オリジナルモデルの他に3つの量子化モデルを紹介します。
オリジナル
ファイルサイズが23.8GBもあります。モデルにアクセスするには、Hugging Faceにログインしてライセンスの同意が必要です。
FP8
- 8ビットの浮動小数点フォーマット
- オリジナル半分ほどのファイルサイズ
GGUF
- 複数のサイズがあるのでVRAMにあわせて選択できる
- 精度や速度について 参考記事
- ComfyUIでの推論は、カスタムノードのインストールが必要
NF4
- FP8の約半分のサイズ(リンクのモデルには、T5, CLIP, VAEも含まれているためサイズが大きい)
- FP8より高速
- FP8 (e4m3fn/e5m2) を上回る精度の可能性 参考記事
- Forgeで推論可能、ComfyUIは対応していない
flux1-dev-bnb-nf4-v2.safetensors
その他に必要なモデル
FLUX.1の画像生成に必要なその他のファイル
T5
メモリが32GB以上ある場合は、FP16の方をお勧めします。
CLIP
VAE
Forgeでの画像生成と比較
Forgeで4つのモデルの画像生成と比較を行いました。生成設定はFLUXを選択したのみになります。
ダウンロードしたモデルを以下に配置します。
- 📁webui\models\Stable-diffusionにベースモデル
- 📁webui\models\text_encoderにT5とCLIP
- 📁webui\models\VAEにVAE
Prompt:A mystical forest illuminated by floating orbs of light, ancient twisted trees covered in glowing moss, a serene river reflecting the soft light. In the center, a graceful elf with long flowing silver hair, dressed in a flowing, nature-inspired robe, stands barefoot on soft moss, holding a glowing staff, exuding an aura of harmony and mystery, surrounded by mythical creatures.




GGUF (Q8)がオリジナルとの変化が一番小さいです。FP8とNF4はそこそこ差異がみられ、NF4の品質が一番悪く感じました。
以下はメモリとVRAMの使用量、生成速度の比較になります。PC環境で変わってくるので参考程度に。
| モデル | メモリ | VRAM | 生成速度 (1step) |
|---|---|---|---|
| オリジナル | 38.0GB | 10.5GB | 5.89s/it |
| FP8 | 27.5GB | 10.5GB | 4.33s/it |
| GGUF (Q8) | 20.0GB | 10.9GB | 4.53s/it |
| NF4 | 15.7GB | 7.5GB | 3.84s/it |
ComfyUIでのGGUF推論
ComfyUIでは、デフォルトでGGUFをロードすることができません。カスタムノードのComfyUI-GGUFをインストールしてください。ComfyUI Managerでインストール可能です。
ダウンロードしたモデルを以下に配置します。
- 📁ComfyUI\models\unetにGGUF
- 📁ComfyUI\models\clipにT5とCLIP
- 📁ComfyUI\models\vaeにVAE
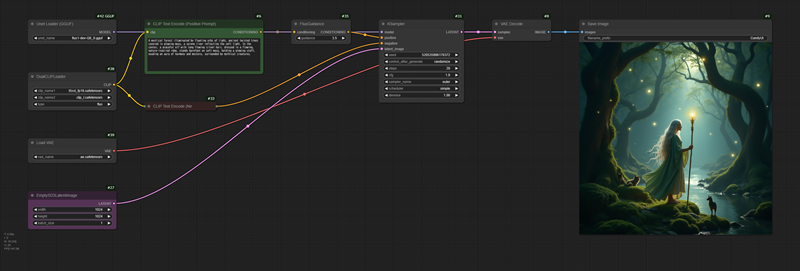
従来のFLUX1のワークフローでLoad Diffusion ModelをUnet Loader (GGUF) に置き換えて使用することができます。画像にワークフローが埋め込まれているのでドロップして使ってください。

