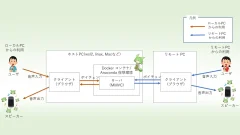
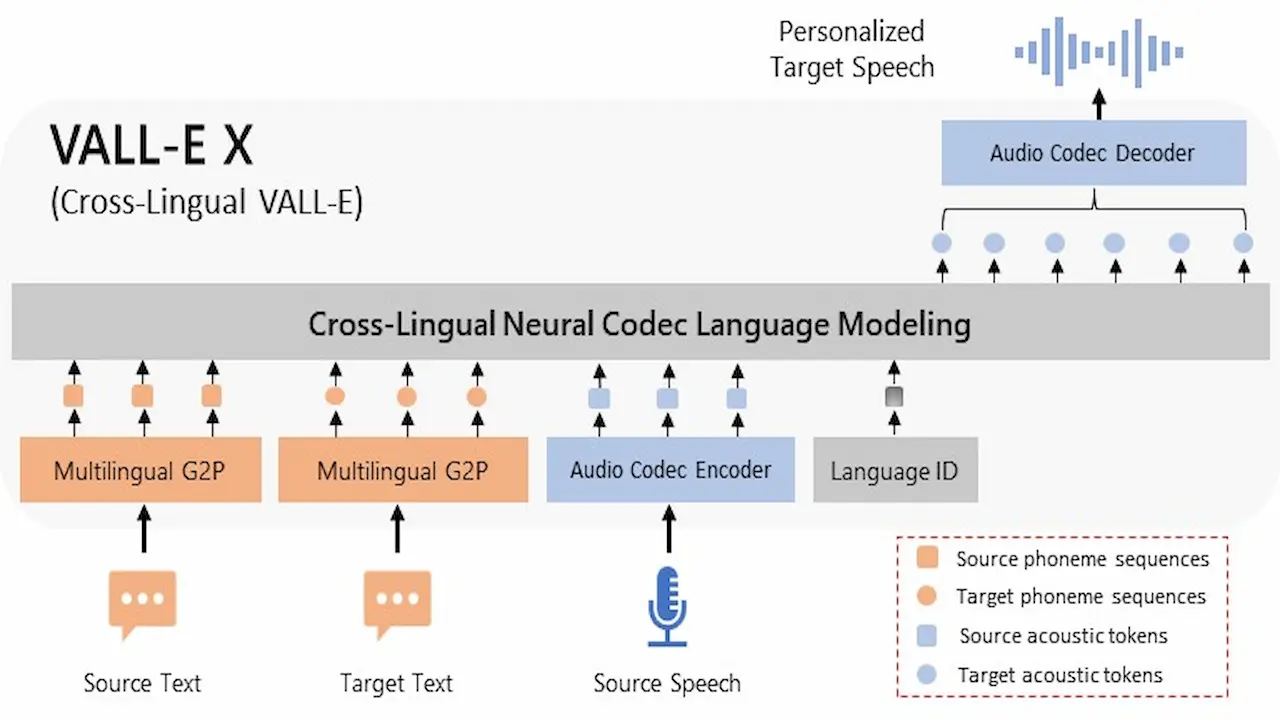
VALL-E Xは、Microsoftが発表した音声合成AIモデル (VALL-E) の技術を再現し独自に訓練したモデルになります。WindowsとNVIDIAグラフィックボード(6GB以上のVRAMが必要)環境でのインストール方法とGUIでの使い方を紹介します。

ソフトウェア要件
インストール前に必要なソフトがあります。
Git
Gitは分散型バージョン管理システムで、GitHubのリポジトリ管理に使用されます。
Miniconda
condaを使用して、仮想環境を作成します。
FFmpeg
音声・動画の処理を行うツールです。
インストール
Anaconda Prompt (miniconda3)を開きます。
GitHubのリポジトリをクローンする
git clone https://github.com/Plachtaa/VALL-E-X.gitディレクトリ移動
cd VALL-E-X仮想環境を作成(Python 3.10 仮想環境の名前はmyenvとした)
conda create -n myenv python=3.10仮想環境をアクティブ化
conda activate myenvPyTorchのインストール(PyTorch2.0.0 CUDA対応バージョン11.8)
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118必要な依存関係をインストール
pip install -r requirements.txt起動
python -X utf8 launch-ui.py次回からの起動方法
コマンドプロンプトを起動してください。
インストールディレクトリへ移動(自身のインストール先フォルダのパス)
cd C:\VALL-E-X仮想環境をアクティブ化
conda activate myenv起動
python -X utf8 launch-ui.pybatファイルの作成
毎回コマンド入力が面倒な方へのbatファイルの作成方法です。
メモ帳を開き以下のテキストを貼り付けたら、名前をつけて保存で拡張子を.batにして保存してください。
@echo off
call conda activate myenv
python -X utf8 launch-ui.py
作成したbatファイルはVALL-E-Xフォルダ内に置いてください。作成したbatファイルを起動することでWebUIまで立ちあがります。
VALL-E Xの使い方
各タブを紹介します。
Infer from audio
音声ファイルを使って生成します。
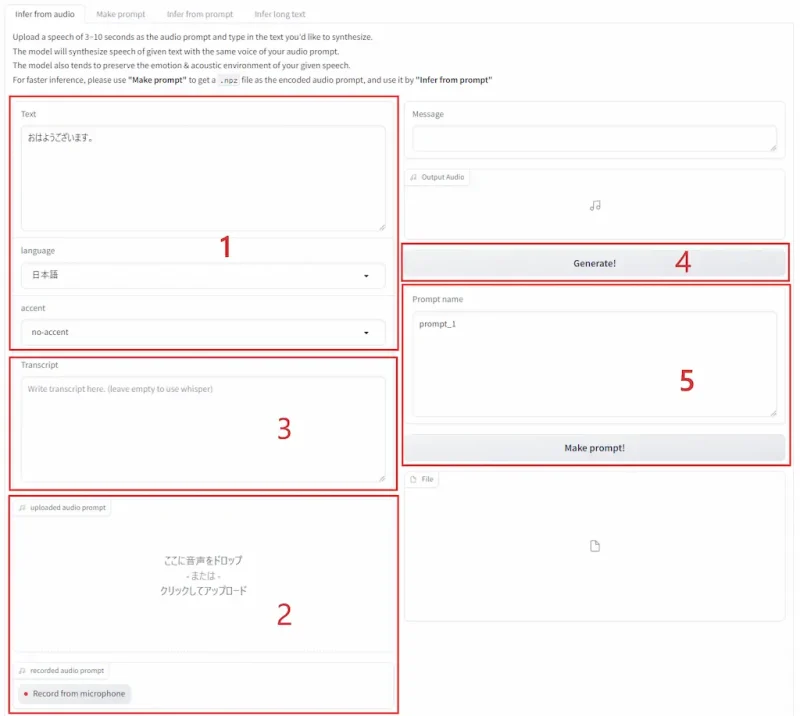
- 喋らせるテキストを入力して言語とアクセントを設定
- 3秒から10秒の音声ファイルアップロードまたは録音する
- アップロードした音声のテキストを入力(空白の場合はWhisperで文字起こしされる)
- 生成する(生成結果は都度違う)
- Make promptをクリックするとnpzファイル(学習ファイル)ができるのでクリックしてダウンロードする。npzファイルを利用すればInfer from audioより早く生成できる
自分で音声ファイルを準備する場合はこちらの記事をご覧ください。

Make prompt
Infer from audioで作成できるMake promptと同じだと思います。どちらで作成してもnpzファイルの容量は同じでした。
Infer from prompt
npzファイルを利用して生成します。
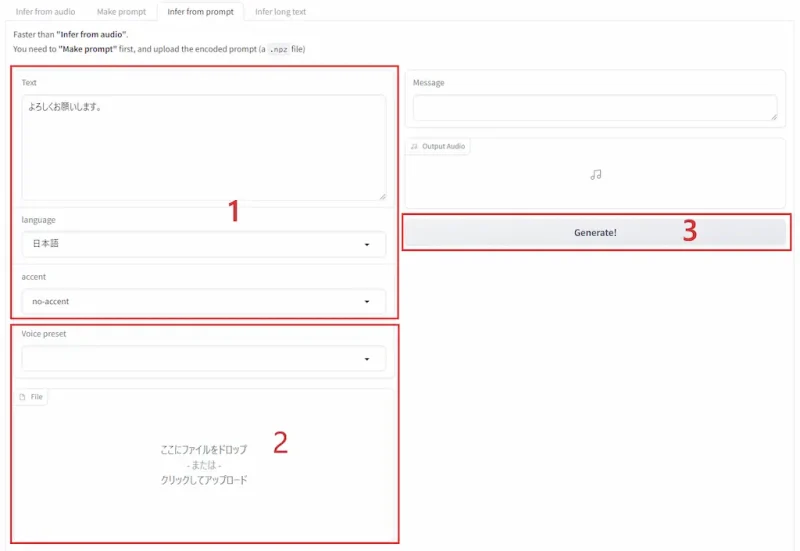
- 喋らせるテキストを入力して言語とアクセントを設定
- npzファイルをアップロードします。また、よく使う学習ファイルはpresetsフォルダ内に保存しておくことでVoice presetから呼び出すことができます。
- 生成する(生成結果は都度違う)
Infer long text
使い方はInfer from promptと変わりません。タブを分けているので長い音声を生成する場合は、こちらからのほうがいいのかもしれません。