
Stable Audio Open 1.0は、リアルなボーカルは生成できませんが最大47秒間の可変長ステレオオーディオを44.1kHzで生成できます。ローカル環境でのインストールと生成を試してみてください。

実行環境
| OS | Windows11 23H2 |
| stable-audio-tools | 7311840dc3ffb69c9134f83483daa1402ec452e3 |
ソフトウェア要件
インストール前に必要なソフトがあります。
Git
Gitは分散型バージョン管理システムで、GitHubのリポジトリ管理に使用されます。
Miniconda
condaを使用して、仮想環境を作成します。
インストール
Stable Audio Toolsをインストールします。Anaconda Prompt (miniconda3)を開いてください。
リポジトリをクローン
git clone https://github.com/Stability-AI/stable-audio-tools.gitディレクトリ移動
cd stable-audio-tools仮想環境を作成
conda create -n stable-audio-tools python=3.10仮想環境をアクティブ化
conda activate stable-audio-toolsPyTorchをインストール
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu118パッケージをインストール
pip install .モデルのダウンロード
Stable Audio Openのモデルをダウンロードします。
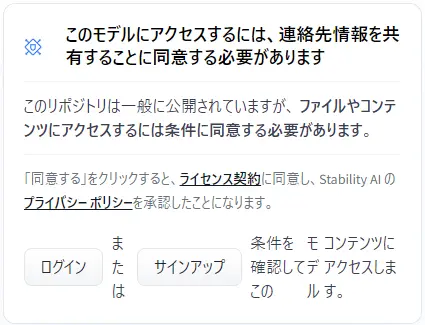
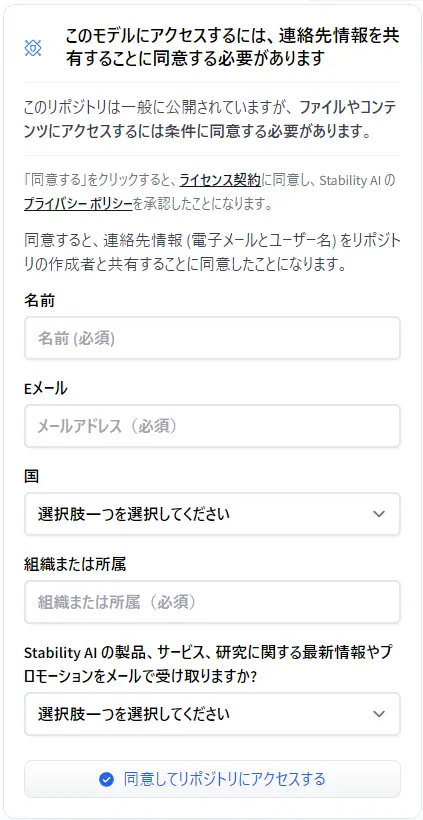
Hugging Faceにログイン後、ライセンス規約に同意し連絡先情報を共有することでモデルにアクセスすることができます。
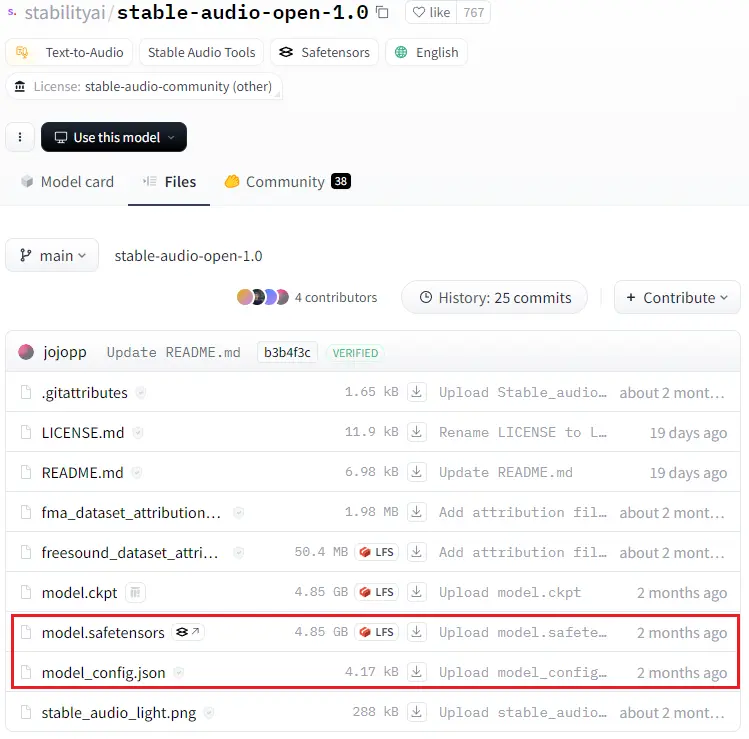
model.safetensorsとmodel_config.jsonをダウンロードします。ダウンロードした2つのファイルは、リポジトリにckptというフォルダを作成してその中に置いてください。
推論
WebUIの起動
python .\run_gradio.py --ckpt-path .\ckpt\model.safetensors --model-config .\ckpt\model_config.json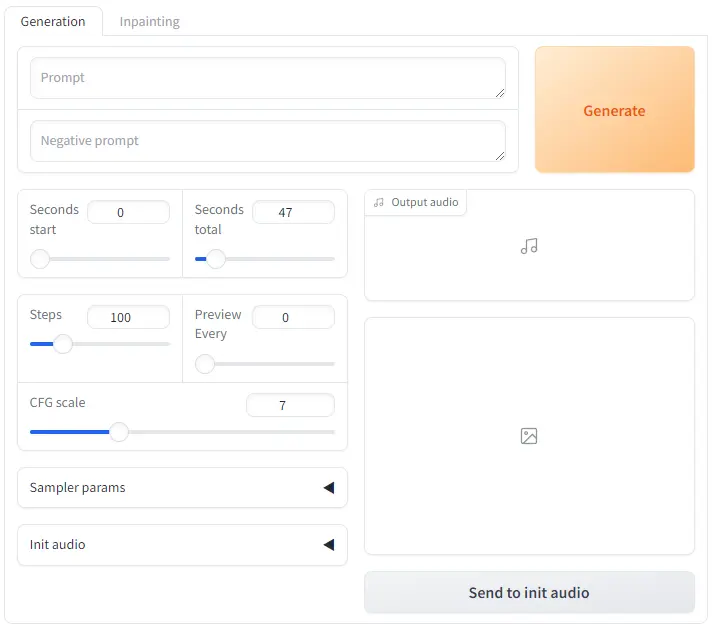
このモデルは、音楽よりも効果音やフィールドレコーディングを生成する方が得意だそうです。以下はChatGPTに考えてもらったプロンプトで生成したサンプルになります。